Naked Objects
By Richard Pawson and Robert Matthews
A critical look at object-orientation
Five practices that separate procedure and data
The continued separation of procedure and data could be ascribed primarily to inertia: that is how most people learned to design systems and they find it hard to think any other way. However, this individual inertia is usually reinforced by a number of specific organizational practices that tend to force the separation of procedure and data even where the software designer wants to adopt a more pure object-oriented approach. We have identified five such practices:
- Business process orientation
- Task-optimised user interfaces
- Use-case driven methodologies
- The Model-View-Controller pattern
- Component-based software development.
To say this is a controversial list is to put it mildly. Several if not all of these phenomena have the status of sacred cows within the systems development community. None of them can be dismissed as simply bad habits. All of them are conscious practices that either clearly deliver a benefit or have been designed to mitigate a known risk in the development process. We are not suggesting that any of these practices is 'bad'; merely that they have the side effect of discouraging the design of behaviourally-complete objects.
However, any alternative practice put forward to counter this separation must not lose the benefits of the incumbent approaches, nor introduce the kind of problems they were designed to overcome.
Business process orientation
Prior to the 1990s, the term 'process' was seldom applied to businesses except those concerned with continuous-process manufacturing such as oil and chemicals. The idea of modelling all business activities in terms of processes became popular in the early 1990s with the idea of business process reengineering [Hammer1993]. After falling out of fashion in the late 1990s, business process thinking is experiencing its second wind, fuelled in part by the emergence of a new generation of business process modelling and management tools See, for example, www.bpmi.org .
Process-orientation really encompasses two ideas. The first is that you should focus on, and organize around, achieving an externally-defined result (such as fulfilling an order) rather than on purely internally-defined activities. This is a useful contribution. The second idea is that processes can and should be reduced to a deterministic procedure for transforming inputs into outputs.
The problem with this notion of process orientation, as John Seeley Brown puts it, is that it tends to become 'monotheistic'[Brown2000]. As more than one interviewee has said to us, 'in our organization, if it isn't a process, management can't even see it'. Such a view is nave and dangerous. Many things that a business does simply don't fit this sort of process model at all: there are plenty of activities where it is not possible to identify discrete inputs and outputs, let alone the sequential steps. Even within domains that can legitimately be described as processes, many of the most important activities, including most management activities and many forms of customer service, fall outside the formal process definitions. (Brown goes so far as to say that the most important people in an organization are precisely those who know how to work around the formal procedures). Social anthropologists draw a useful distinction between 'process' and 'practice', an enormous subject that is outside the scope of this book.
One of the causes of this obsession with processes is the 'Porter' value chain [Porter1985]. Michael Porter proposed this as a universal model of business: margin is created through a sequential set of value adding stages. It is clear how this applies to, say, General Motors, but Porter argued that the same model applies to a bank, where 'inbound logistics' is deposit taking, 'outbound logistics' is lending, and so forth.

The Value Chain model of business, as proposed by Prof. Michael Porter in the early 1980s, is seen by many to be a universal model of business value creation. This model reinforces a process-oriented style of thinking. However the universal validity has since been strongly challenged. |
This idea has since been challenged by Charles Stabell and Oystein Fjeldstadt[Stabell1998] who say that the value chain is actually a very poor model of many businesses, and its use can lead to dangerous mistakes at the strategic level. They suggest that there are three different mechanisms through which businesses create value: the value chain, the value shop and the value network. They also argue that the proportion of businesses that fit the chain model is declining rapidly. Value shops (such as consultancies, builders, and primary healthcare organisations) create value by applying resources to solve individual problems. Their activities seldom follow a linear sequence and are often iterative in nature. Value networks (which include many telecommunications, banking and insurance companies) create value by selling customers to each other. Their value creation shows significant network effects, which is not the same thing as the 'economies of scale' pursued by value chains.
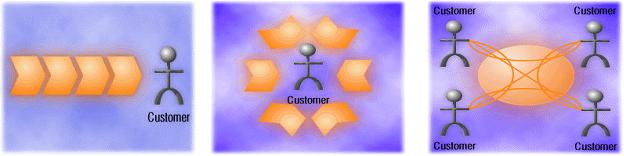
Stabell and Fjeldstadt argued that there are three fundamental models of business value creation: the value chain (left), the value shop (centre) and the value network (right). The shop model, in which resources are organised around solving an individual problem, and which represents a growing proportion of businesses, typically suffers from poor IT support. |
The value chain concept emphasizes the sequential addition of value to input materials. This fits well with the software paradigm of separating the value adding procedures from the inanimate data that they operate on. If you ask IT professionals to define what an information system is, many will say it is a mechanism for transforming input information into output information through the successive application of smaller transformations. Historically that may have been an accurate description, but it is a very poor way to describe many modern IT capabilities, which are much closer conceptually to a value network or a value shop model. Metaphors that compare the role of information systems to a production line only add to the problem.
Task-optimized user interfaces
The same line of thinking occurs at a much smaller scale in the design of user interfaces. Most user interfaces are designed to implement a finite set of scripted tasks. This is not only implicit in the user interface design methodology, but more often than not it is also made explicit in the resulting design: the user is presented with a menu of tasks and then guided through the chosen task, selecting from sub-options as required. This style of user interface is convenient for systems developers because it maps easily onto a set of defined transactions, which in turn manipulate data structures.
Another driver behind this approach is the idea that scripting is the key to optimization. This can be traced directly back to Frederick Taylor and his principles of scientific management [Taylor1911] (see panel).
|
The legacy of Frederick Winslow Taylor 
Frederick Taylor's quest for 'the one best way' of working began with the technology itself. In the machine shop where he worked, initially as an artisan and then as a foreman, he conducted thousands of experiments to find the optimum cutting speeds for various kinds of machine operation. His results showed significant improvements in possible productivity rates compared to the rule-of-thumb methods in use by the workers of the day. His next target was the organization of the work. Again using thousands of experiments he sought to find the optimal answer to every aspect of organizing manual work: from the optimal size of a shovel to the optimal frequency of work breaks. To encourage workers to adopt his best practices, he advocated the introduction of differential piece rates, where the incremental rate of pay rose with performance. Still Taylor was not satisfied. The workers were making use of his techniques, but not consistently. The solution was to remove all the decision rights from the workers: to script their every action. Taylor realized that the workers would not give up their self-determination lightly. To get them to do exactly his bidding - to order their tasks as he said, arrange their space as he said, work when he said, and rest when he said - he would need to increase their overall rate of pay. The amount of this pay increase was just another value to be determined scientifically: it turned out to be 35%. Biographer Robert Kanigel calls this the 'Faustian pact' (Kanigel 1997). Taylor believed that he was empowering the workers, in the specific sense of empowering them to earn a better living. But in the modern sense of the word, he was clearly dis-empowering them. Taylor's scripted instructions were provided on index cards. We can only speculate how he might have reacted to modern information technology, but we suspect that he would have been delighted by its capacity for extending his methods in both their range and their reach. Most business systems treat the user as simply a process-follower. The system controls the whole procedure, subcontracting to the user only those subtasks that it is not able to fulfil autonomously. |
Barbara Garson suggests in her book, 'The Electronic Sweatshop: How Computers turned the Office of the Future into the Factory of the Past' [Garson1988], that this paradigm isn't necessarily even driven by efficiency: 'I had assumed that employers automate in order to cut costs. And indeed cost cutting is often the result. But I discovered in the course of this research that neither the designers nor the users of the highly centralized technology I was seeing knew much about its costs and benefits, its bottom-line efficiency. The specific form that automation is taking seems to be based less on a rational desire for profit than on an irrational prejudice against people.'
The alternative is to design systems that treat the user as a problem solver. Most businesses already have some systems that are problem-solving in nature. All drawing programs, from PowerPoint through to complex CAD/CAE systems, take this form, as do spreadsheets. However, in most businesses these systems are not considered to be 'core'. The core systems are typically concerned with processing standard business transactions, and they are optimized to a finite set of tasks, which are almost always implemented as scripted procedures.
|
The Incredible Machine (www.sierra.com) is a great example of a problem-solving system, and one that clearly reveals its object-oriented structure to the user. The user is presented with a problem to solve - in this case, pop the silver balloon ... 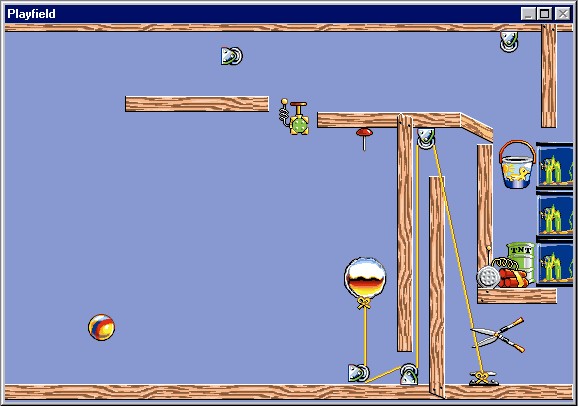
... using any of the available parts (objects), each of which can be inspected to reveal its physical properties and behaviours: 
First, we use an anti-gravity pad and a block of wood to bounce the ball onto the plunger ... 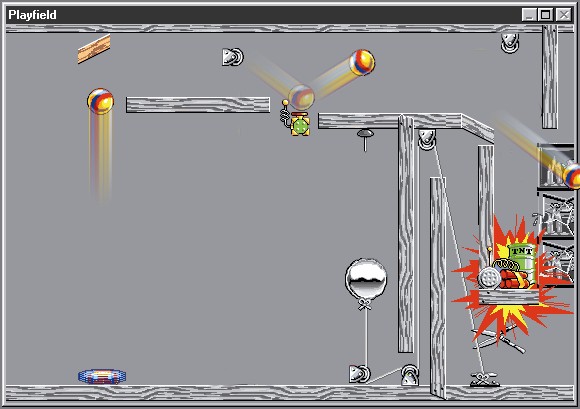
... which will detonate the TNT by remote control. Using a rope and two pulleys and a counterweight, we tie up the bucket so that it will catch the ball: 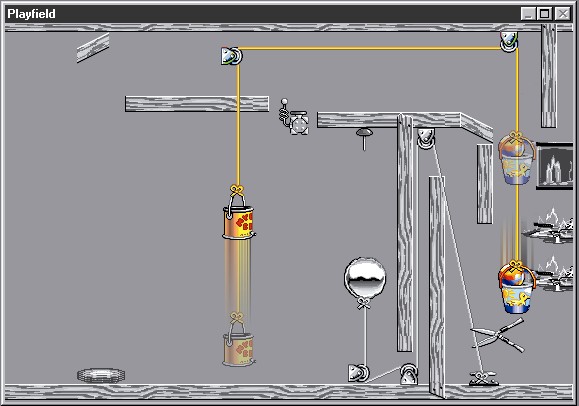
The counterweight is a leaky bucket, and when enough water has leaked out, the bucket and ball fall onto the shears, releasing the balloon, to pop itself on the pin above: 
|
Many people feel that problem solving and transactional systems reflect two very different needs within the business, that there is no need to merge the two, and that doing so would likely de-optimise the processing of the standard tasks that represent the bulk of business activities. We suggest that there is a very real need to bring the two ideas closer together: in other words to make even core transactional systems as 'expressive' as a drawing program[Pawson1995].
Bringing these two ideas together does not mean just putting graphical user interfaces on core transactional systems. In fact, as several airlines discovered to their cost, the first generation of GUI-based reservation systems were in fact less expressive than the old style command line interfaces - which may have been difficult to learn, but afforded the user a high degree of control. Such experiences can give rise to the wrong conclusion that 'users don't really like GUIs'. What users really don't like is bad GUIs.
Another prejudice is that introducing more expressiveness into core transactional systems will reduce efficiency. This may be true in the narrow context of specific standard tasks, but in a broader sense efficiency can actually increase.
Consider the area of customer service. Everyone can relate to the frustration of dealing with a customer service representative, perhaps in a call centre, where the whole interaction is both defined and constrained by the computer system's script. Sometimes the problem that the customer wants to solve (using 'problem' in the broadest sense of the word) does not seem to fit one of the standard scripts; or tasks cannot be fulfilled without an unpredictable number of side-excursions in completing a task-step; or the customer would prefer to give the information in a different order from that which the computer expects. Most frustrating of all is when the customer needs an intermediate result to be able to answer a question:
- Customer: How long does it take to get from London to Sydney?
- Agent: What date are you leaving London?
- Customer: That depends on what my options are for getting to Sydney ...
This approach to tightly-scripted interactions is becoming ever more common (and frustrating). In customer service, an increasing proportion of 'standard' problems are now addressed through self-service. If the customer just wants to order a book, report a fault on a telephone line, or check-in to a flight, then a web-interface, interactive voice-response system, or kiosk, respectively, can handle it. It follows that a growing proportion of calls or visits to a customer service centre are about non-standard problems, or are from people who simply do not wish to work within the narrow confines of such an approach. And yet call centre systems continue to strive to shave seconds off the average call length by 'optimizing the script'.
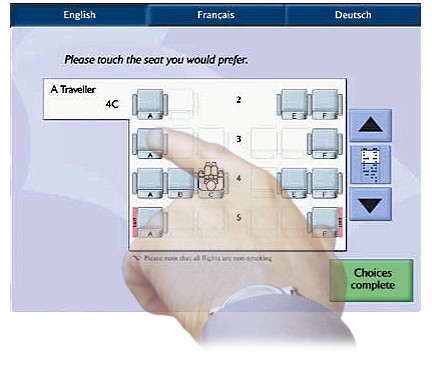
Self-service check-in systems, such as this one by British Airways, can now handle standard check-in procedures. It follows that the systems available to the staff at the check-in desks need to be geared primarily towards individual problem solving, not standard procedures. |
Use-case driven methodologies
The concept of a use-case was defined by Ivar Jacobson as 'a sequence of transactions in a system whose task is to yield a measurable value to an individual actor of the system'[Jacobson1995]. A use-case driven approach to systems development writes use-cases that capture the requirements of a system, and then seeks to identify the common objects from them. The most popular object-oriented methodologies are use-case driven.
The case against use-cases is well summarized by Don Firesmith [Firesmith1996]: 'Use cases are not object-oriented. Each use case captures a major functional abstraction that can cause numerous problems with functional decomposition that object technology was supposed to avoid . . . . Since they are created . . . . before objects and classes have been identified, use cases ignore the encapsulation of attributes and operations into objects.' He goes on to say that a use-case driven approach results in 'the archetypal subsystem architecture . . . a single functional control object representing the logic of an individual use-case and several dumb entity objects controlled by the controller object . . . Such an architecture typically exhibits poor encapsulation, excessive coupling, and an inadequate distribution of the intelligence of the application between the classes'.
Jacobson also saw use-cases as serving another purpose: testing the resulting system. 'The use cases constitute an excellent tool for integration test since they explicitly interconnect several classes and blocks. When all use cases have been tested (at various levels) the system is tested in its entirety' [Jacobson1992]. This concept has no negative impact on the quality of the object modelling, and we would consider this to be good practice.
We suggest that use-cases are most powerful when they are written in terms of operations upon objects that have already been identified and specified, and are used to test that object model. Conversely, use-cases are most dangerous when they are written before the object model and used to identify the objects and their shared responsibilities - which is precisely what use-case driven approaches advocate.
The question then arises: how are the business objects to be identified? The answer is through direct and unstructured conversations between the users and developers. The idea of direct interaction or the 'on-site customer' is advocated by all of the modern 'agile' methodologies, though not specifically to enable what has been suggested here. There is ample evidence that good object modellers, given a context like this, are able to identify the objects directly without the need for other formal artefacts [Rosson1989].
The criticism levelled at this approach is that it depends upon expert object modellers. By contrast, systems development methodologies are designed to avoid the need for such expertise. (In fact, there is a kind of vicious circle: prescriptive methodologies reduce both the need for, and the possibility of, design intuition.)
We suggest that our approach does not need super-human object modelling expertise. All it really needs is the right medium to capture an emerging object model in the form of a working prototype that both users and developers can understand and contribute to. This does not mean a conventional prototype that captures the user's task requirements in terms of forms and menus, but a prototype of a object-oriented user interface (OOUI), where what the user sees on screen bears a direct relationship to the underlying business objects - in terms not only of attributes and associations, but also of behaviour. Previous work relating to this concept includes IBM's Common User Access [IBM1991] and OVID methodology [Roberts1998], and Oliver Sims' work on Newi and the 'Lite' version Business Object Facility[Sims1994] [Eeles1998].
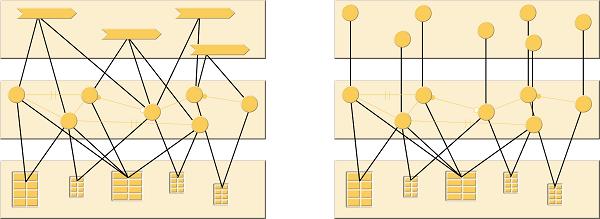
(Left) With use-case driven approaches there is a strong tendency for the use-cases to end up being implemented as explicit software constructs (top layer) that mask the objects (middle layer) from the user. The result is that natural responsibilities of the business objects get usurped by the user-interface layer. (Right) By adopting an object-oriented user interface (OOUI) it is possible to preserve a 1:1 correspondence between the constructs of the user interface and the underlying business object model. This helps to maintain the concept of behaviourally-complete business objects. |
The Model-View-Controller pattern
As discussed in the previous point, use cases get translated all too easily into controller objects that sit on top of dumb entity-objects. This effect is reinforced by a common architectural pattern that explicitly separates three roles: the core business objects that correspond to business entities, objects that provide the user with views of the model, and objects that control the interaction between the user and the model. One version of this pattern is Model-View-Controller, or MVC [Krasner1988]; another (as used in the Unified Process) is Entity-Boundary-Controller [Jacobson1999]. There are subtle distinctions between these two patterns, but they are broadly similar. We shall use MVC as an example.
The motivation for using MVC is the separation of concerns. The argument is that any given core class of business object will be viewed in many different ways: on different platforms, in different contexts, and using different visual representations. Embedding knowledge of all these different views, as well as the knowledge of how to effect them, into the business objects themselves would make for bloated objects and heavy duplication of functionality between objects. Using MVC, the Model objects have no knowledge of these different views. Dedicated View objects specify what is to appear in each view, and in what form, and have the know-how to create the visual display. Controller objects provide the glue between the two: populating the views with attributes from the business entity objects, and invoking methods on those objects in response to events from the user.
This is sound thinking, but it has some negative side effects. Although it is not the original intent of the MVC approach, the Controller objects tend to become an explicit representation of business tasks - especially if the design approach is use-case driven, but also in other cases. When that happens the role of the Controller objects ceases to be limited to the technical 'glue' between the user interface and the business objects. Increasingly they take on the role of task-scripts, incorporating not only the optimized sequence of activities, but business rules also - thereby usurping what ought to be responsibilities of the core business objects. And whilst the View objects cannot be said to contain business logic in the sense of algorithms, they can nonetheless end up incorporating a form of business-specific knowledge in the selection and layout of fields presented for a particular task, and (sometimes) minor business logic such as maintaining a running total of entered data.
The net effect is that business-specific knowledge is scattered across the model, view and controller domains. Any change to the core business object model will potentially entail changes to a large set of the View and Controller objects [Holub1999]. Of course this problem is not restricted to object-oriented design - it applies to most forms of multi-tiered architectures. Also, there is nothing inherent in MVC that forces this trend, but the fact that it is common practice suggests that the pursuit of behaviourally-complete objects requires an explicit means to counter it.
As with the other forces, any alternative proposal must avoid falling into the trap that MVC was designed to avoid: it must still be easy to port an application across multiple technical platforms and even multiple styles of interaction, without requiring the business model to be edited. At the same time, it must accommodate the need for multiple visual representations of the model on the same platform, where these are genuinely needed. The use of the word 'genuinely' is a reference to a minority but growing belief that the emphasis in recent years on user-customisation has become excessive: that it consumes vast development resources with limited benefits. As Raskin points out [Raskin2000], what is the point of a vendor investing heavily in the design of user interface patterns to maximize comprehensibility and minimize stress, only to let the user, or the user's agent, customize those benefits out again?
Instead, supply a generic viewing mechanism, embodying the roles of View and Controller objects. This means writing a viewing mechanism for each required client platform (Windows, Linux, web browser or Palm Pilot, for example). But once a generic viewing mechanism exists for the target platform, all a developer needs write are the business Model objects. The generic viewing mechanism automatically translates the business Model objects, including the available behaviours, into a user representation. The Model objects and their various associations might show up as icons, for example, with the methods or behaviours made available as options on a pop-up menu. This approach does not violate the essence of MVC, but is a radical reinterpretation of how to apply it. One way to look at this is that it renders the View and Controller objects agnostic with respect to the Model, as well as vice versa.
The idea of auto-generating the user interface from an underlying model is not new. The concept existed in many proprietary fourth-generation languages and application generators, and is re-emerging in various XML-based initiatives such as the W3C's Xforms. However, few of these approaches are object-oriented: the user interface is typically an explicit representation of data structures and functional modules or processes. They continue to encourage the separation of procedure and data.
Perhaps the closest approach to our solution, and certainly one of the best challenges to the hegemony of MVC, is the Morphic user interface [Maloney1995]. Using Morphic, application objects can inherit the ability to render themselves visible to, and manipulable by, the user. Morphic was originally developed as part of the Self language [Smith1995], and subsequently taken forward within the Squeak language [Ingalls1997] - see figure. Squeak provides the user with a very strong sense of direct interaction with the application objects themselves. The user can select any object and invoke display-related as well as business-specific behaviours directly - even when the objects are moving around the screen. Hence Squeak has blurred the line between programming and using a system. However, although Squeak clearly has general-purpose potential (in the words of the Squeak central team, Squeak is 'Smalltalk as it was meant to be'), most of the emphasis to date has been on educational applications, animated graphics, and multi-media authoring tools. It has yet to be applied to the design of transactional business systems.
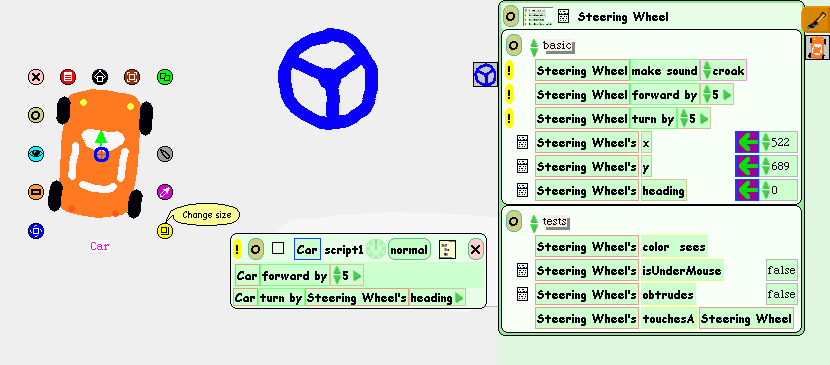
The Morphic user interface, originally developed as part of the Self language and now adopted by Squeak (pictured) is one of the most comprehensive challenges to the Model-View-Controller paradigm. All Morphic objects inherit the ability to display themselves and to render their behaviours visible and accessible. As shown in this screenshot, when the user clicks on an object (in this case the red car), it displays a 'halo' of small icons around it, which provide standard manipulation functions. See www.squeak.org and www.squeakland.org for more details of this exciting open-source project. |
Component-based systems development
We are not opposed to the idea of component-based systems development, but we are concerned about the way in which this idea gets confused with object-oriented design. Certainly they have elements in common, just as any two ideas in software development have elements in common. But object-oriented design and component-based systems development are quite different concepts.
Component-based systems development is primarily concerned with enabling a plug-and-play approach to systems development. Plug-and-play gives you, in theory, more flexibility in sourcing your systems: you will be able to purchase components on the market, copy them from a public library, or re-use components that you have written in-house with multiple applications in mind. Such flexibility can potentially save direct expenditure, reduce development effort, improve quality, and promote standardization.
Object-oriented modelling is not, or should not be, concerned with plug-and-play. It is concerned with matching the structure of the software to the structure of the real-world business domain that the system is modelling. The motivation is to make it easier to change that model, either periodically in response to changing business requirements, or dynamically in response to a particular problem.
The components model has been very successful at the level of technical services - in the sense that you can now change your database without necessarily having to change other layers in the architecture. At the business level there is now a much greater degree of compatibility between application suites: you can choose your manufacturing planning package independently of your parts ordering system and so forth. But attempts to decrease the granularity of business components have been much less successful. Where it has happened at all, the components have not ended up looking like objects - at least in the sense of behaviourally-complete instantiable entities - but like sub-routines - chunks of code that can transform an input into an output. This form of components marries well with the idea of business process modelling, neatly completing the circle.
There have been some attempts to marry the concept of business objects with plug-and-play software assembly (notably by Oliver Sims and colleagues[Eeles1998] [Herzum2000]). However, combining two paradigms into one is always risky: the more widely accepted paradigm (assembly of components) is likely to dominate the less well accepted one (behaviourally complete objects). Our view is that these two concepts are best kept apart. Apply the concept of component assembly to your technical infrastructure, and stick to pure object modelling for the business layer.
Arguably, one of the main reasons why so many organizations have come down on the components side of the 'object vs. components' debate is that they have developed an almost pathological fear of doing their own design and development. They have painful memories of analysis paralysis, of drawn-out development, and of systems finally delivered to specification but failing to address the real business need. We hope to demonstrate that it doesn't have to be that way. Developing your own business object model need not be a painful experience at all.
Copyright (c) 2002 nakedobjects.org You may print this document for your own personal use, or you may copy it in electronic form for access within your organisation, provided this notice is preserved.