Naked Objects
By Richard Pawson and Robert Matthews
A critical look at object-orientation
A brief history of objects
The concept of object-oriented software is almost forty years old. Over that period the ideas have evolved considerably, and this evolution can be roughly split into four phases:
- Simula and the birth of object-oriented programming
- Smalltalk and the object-oriented user interface
- The emergence of object-oriented methodologies
- Distributed object infrastructures.
Simula and the birth of object-oriented programming
The idea of object-oriented software originated in Norway in the mid 1960s with Simula, an extension to the Algol programming language. Simula was designed to make it easier to write programs that simulated real-world phenomena such as industrial processes, engineering problems, or disease epidemics [Dahl1966].
Previously, all programming languages and techniques explicitly separated a system into procedure and data. Their assumption was that a computer system repeatedly applies the same procedure to different data.
Simulation challenges that assumption. Sometimes the data is fixed and the programmer manipulates the functional characteristics of the system until the output meets the required criteria. For example, the data might represent the roughness of a typical road and the programmer might alter the design of a simulated truck suspension system until the desired quality of ride is achieved. Sometimes it is even difficult to tell data and functionality apart: when you add another axle to your simulated truck, for example, are you changing the data (the number of wheels) or the functionality (the way in which the truck translates road bumps into ride quality)?
The inventors of Simula had the idea of building systems out of 'objects', each of which represents some element within the simulated domain. A simulation typically involves several classes of object - a Wheel class, a Spring class, a Chassis class, and so forth. Each class forms a template from which individual instances are created as needed for the simulation.
Each software object not only knows the properties of the real-world entity that it represents, but also knows how to model the behaviour of that entity. Thus each Wheel object knows not just the dimensions and mass of a wheel, but also how to turn, to bounce, to model friction, and to pass on forces to the Axle object. These behaviours may operate continuously, or they may be specifically invoked by sending a message to the object.
We call this principle 'behavioural completeness'. This does not mean that the object must implement every possible behaviour that could ever be needed. It means that all the behaviours associated with an object that are necessary to the application being developed should be properties of that object and not implemented somewhere else in the system.
The word 'encapsulation' is often used in this context. The word has two meanings in English. The first has to do with being sealed, as in a medicinal capsule or a time capsule. This is how many people use it in the context of object-orientation: an object is sealed by a message-interface, with the internal implementation hidden from view. This is an important property of objects, but it is not unique to them. The ideas of black-box operation and of 'information hiding' are common to many forms of component-based systems development. The second meaning of encapsulation is that something exemplifies the essential features of something else, as in 'this document encapsulates our marketing strategy'. This second meaning - which corresponds to the principle of behavioural completeness - is far more important in the context of object-oriented modelling.

The Shorter Oxford Dictionary reveals the two meanings of the word 'encapsulation'. In the context of object-orientation most people assume the first meaning, but it is the second meaning that is more important. |
The value of behavioural completeness is that any required changes to the application map simply onto changes in the program code. For example, adding a valve between two pipes in a Simula model of an oil refinery simply involved creating a new instance of the Valve class, setting its operating parameters, and linking it to the appropriate Pipe objects. The new valve object brought with it the ability to be opened and closed, altering the flow of oil appropriately, as well as to model the impact on construction costs. If the same refinery were modelled using a conventional programming language, the various behaviours associated with the valve would likely be distributed around the program and therefore harder to find and change.
Smalltalk and the object-oriented user interface
Although the Norwegian work continued for many years, by the early 1970s a new stream of object-oriented thinking was emerging from Xerox's new Palo Alto Research Center (Parc). Alan Kay, who led the Learning Research Group at Parc, was attracted to object-orientation for several reasons. The first had to do with scalability. At that time, lots of people were worrying about software scalability, but what most of them meant was scaling up by one or two orders of complexity.
But in 1965, Gordon Moore, who later co-founded Intel, had written in Electronics magazine that the number of transistors on an integrated circuit would continue to double every year for at least 10 years. The actual trend has been closer to doubling every two years, but it has continued unabated to the present day. Kay was one of the few researchers to take the implications of the newly-coined Moore's Law seriously, and he was interested in how software complexity could scale up by a factor of a billion to take advantage of this hardware. Kay's conception of the future of computing - of notebook-sized computers with wireless connections into a gigantic network of information - looked like pure science fiction back in the early 1970s.
Drawing an analogy from microbiology, Kay argued that the only way that software could scale up in complexity by a factor of a billion would be if the software was self-similar at all scales: that the most elementary software building blocks were, in effect, complete miniature computers - in other words, 'objects'.
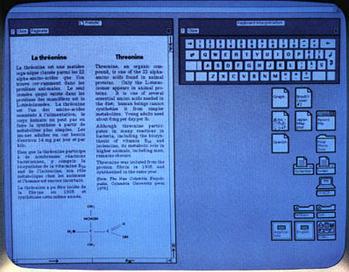
The first real application of this potential complexity lay in the user interface. Graphical user interfaces were not a new idea: Ivan Sutherland had demonstrated many of the key ideas in both graphical output and direct-manipulation input with his Sketchpad system in 1963 [Sutherland1963] but his ideas were not easy to generalize into other applications. By the early 1970s the falling cost of processing power made it possible to create similar effects in pure software using bit-mapped displays. The team at Parc used object-oriented programming techniques to manage hundreds of graphical objects on a bit-mapped display simultaneously, each monitoring and reacting to changes in other objects it was associated with, or to user-initiated events such as mouse movements. Although there were hundreds not billions of objects, this was already way beyond the complexity that could be achieved using conventional programming approaches.

Ivan Sutherland's Sketchpad, developed in 1963, introduced the ideas of both graphical output and direct-manipulation input. In many ways, Sketchpad anticipated the ideas of object-oriented user interfaces, but it did not prove easy to generalize. |
Kay also saw that the concept of objects had enormous potential as a cognitive tool: they corresponded well to the way people think about the world [Kay1990]. He noted that whereas an isolated noun conjures up a concrete image in people's minds (think of an apple), an isolated verb typically does not (try to visualise 'run'). This is because verbs are effectively properties of nouns: the boy runs, the dog runs, the water runs, the trains run. This gave rise to the object-oriented principle known as 'polymorphism': you can issue the same command (verb) to different objects, but it is up to the object to decide how to execute that verb.
One product of this way of thinking was the language Smalltalk [Kay1996]. Although it subsequently grew into a full-blown programming language, still revered by many as the purest form of object-oriented programming, the original idea of Smalltalk was a language that young children could use to instruct a computer to perform simple tasks and then build these into more complex tasks.
Another result was what we would today describe as an object-oriented user interface or OOUI. Unfortunately, this term has been diluted over the years. For example, one of the most popular references on OOUI design [Collins1995] uses the example of the simple calculator application, contrasting an old-style command-line version with the now-familiar accessory supplied with both the Windows and Mac user interfaces. Such a calculator has a graphical user interface (a picture on the screen), makes strong user of metaphor (it looks just like a real-world calculator), and uses direct-manipulation [Schneiderman1982] (you point and click on the buttons). All these concepts have come to be associated with OOUIs, but they are merely by-products. The essence of an OOUI is that the user can refer to individual objects, and identify and invoke object behaviours directly upon those references. One effective implementation of this represents the objects as icons, and the behaviours as actions on a pop-up menu. However, it is perfectly possible to have an object-oriented user interface where the user's interaction is via a command-line, provided that the form of those commands is object-action (i.e. noun-verb). In fact some of the earliest examples of using Smalltalk for teaching purposes took this approach.
These concepts were first implemented in the Alto, an experimental machine that would become known as the first personal computer. The first commercial realization was in the Xerox 8010 or 'Star' workstation, which came with a fixed set of applications for word processing, drawing, and other document-related functions. The Alto and Star directly inspired the creation of the Apple Lisa and Macintosh [Levy1994], and subsequently Microsoft Windows and Office, and a wide range of other systems.
The Xerox 8010 'Star' Workstation was the first commercial realisation of the ideas on object-oriented user interfaces developed at Xerox Parc in the early 1970s. |
Yet although the ideas of a desktop metaphor, icons, and overlapping windows are now pervasive, many of the most powerful ideas have been ignored, distorted, or diluted to the point where they have no value. Most of the applications now written to run within modern GUI environments show little evidence of object-oriented thinking. Consider two examples.
First, icons were conceived at Parc as representing instantiable nouns, yet today icons are mostly used on toolbars to represent actions or verbs. This may not be a bad idea in itself, but it distracts many developers from the more important concept of icons as nouns, where the icon indicates the properties and behaviours that can be invoked upon the item in question.
Second, in most cases there is a static menu-bar at the top of the screen instead of pop-up menus, which means the verbs and the nouns are physically separated. Both the Windows and Mac operating systems now support pop-up menus but, intriguingly, these are often referred to as 'short-cuts', implying that the primary locus of action is elsewhere.
Some people retort that in (for example) a word processor, many actions apply to the document as a whole rather than to an individually selectable object. All this implies is that the designers must provide either an easy way to select the document as a whole, or a direct iconic representation of the whole document with its own pop-up menu.
A few applications picked up the original object-oriented concepts and ran with them, but they were almost all concerned with graphic design, desktop publishing and other document-related activities. Neither the original Parc researchers, nor their immediate spiritual successors in Apple, showed much interest in the world of transactional business systems that accounted for by far the bulk of computer users, worldwide, at that time. Instead, object-oriented techniques worked their way into mainstream business systems development in the form of analysis and/or design methodologies.
The emergence of object-oriented methodologies
The first methodologies that embodied object-oriented principles and could be applied to mainstream business systems started to appear in the late 1980s. They had common features, but also subtle differences, each with specific advantages or applicability.
Many of these methodologies applied object-oriented concepts to an existing practice. For example, Shlaer and Mellor's Object-Oriented Systems Analysis [Shlaer1988] and Rumbaugh's Object Modelling Technique [Rumbaugh1991] both evolved from data modelling techniques. To put this in the most positive light, these methods supported the fledgling notion of object-oriented analysis and design with proven techniques from software engineering. But conversely it can be argued that they brought with them a great deal of baggage that encumbered the object-oriented approach.
Despite the claims that these methodologies were well suited to mainstream business systems development, many of them were originally designed to meet the needs of large-scale engineering systems, such as defence systems (in the case of Booch's Object-Oriented Design [Booch1986]) or telephone exchanges (in the case of Jacobson's Object-Oriented Software Engineering [Jacobson1992]). Some of the characteristics of engineering systems are considerably more demanding than those of business systems, in particular real-time performance, reliability, and safety-related issues. However, in other respects engineering systems are easier to design than business systems. The requirements for software in engineering systems will, in many cases, be specified by product engineers rather than by nave customers; and even though the requirements may change as the overall design evolves, it is not too hard to get a reasonable first cut at the requirements specification. To those who have undertaken requirements gathering for business systems, this sounds like luxury.
In the following decade several of these methods began to converge. The Unified Modeling Language (UML), emerged as the standard way to represent object-oriented designs in graphical form, and three of the methodology pioneers (Booch, Jacobson and Rumbaugh) collaborated to specify the Unified Software Development Process[Rumbaugh1999].
One approach that still stands alone is Rebecca Wirfs-Brock's notion of Responsibility-Driven Design (RDD) [Wirfs-Brock1989]. Although not fundamentally incompatible with the other methodologies, RDD places far more emphasis on the notion of object responsibilities. It teaches that objects should be conceived solely in terms of the responsibilities that they would be expected to fulfil. These can be broadly divided into things that the object is responsible for knowing, and things that the object is responsible for doing, with as much emphasis as possible placed on the latter. (Strictly speaking, even the 'know-whats' are specified in terms of what an object should know from an external perspective, not what it may or may not store internally). The use of Class-Responsibility-Collaboration or CRC cards [Beck1989] is a useful technique for recording these responsibilities during the early stages of analysis and/or design. The significance of both the formal approach of RDD and the lightweight technique of CRC cards is that they encourage the notion of behavioural completeness. As we shall see shortly, that is much less true of other methodologies.
By the beginning of the 1990s there were a number of successful large-scale business systems designed using object-oriented approaches. But the demands of object-orientation in terms of memory management and processing power relative to the capabilities of hardware and operating systems of the era posed substantial technical challenges, and pioneering organizations found themselves having to design significant amounts of new technical infrastructure from scratch. That would change in the 1990s.
Distributed object infrastructures
During the 1990s the emphasis switched onto the infrastructural technologies necessary to support enterprise-level object-oriented business systems, including commercial versions of the Smalltalk language, object-oriented databases, and various kinds of middleware to support distributed objects. The formation of the Object Management Group led to the specification of the Common Object Request Broker Architecture (CORBA), and a series of other public standards, which would eventually be implemented in dozens of products. Two proprietary technologies, Microsoft's DCOM/COM+ and Sun's EJB/J2EE, also developed substantial installed bases during the 1990s. All three of these technologies provide the infrastructural services needed to implement object-oriented systems on an enterprise scale, including persistence, distributed communication, security and authorization, version control, and transaction monitoring.
All three of these technologies make heavy use of object-oriented principles such as encapsulation (in the first of the two meanings described earlier), message passing, polymorphism, and in some cases even inheritance. Yet they were not primarily conceived with the intent of facilitating a greater commitment to behaviourally-complete objects. Their main intent was to enable distributed systems, implement layered architectures, and achieve platform independence.
The second half of the 1990s also saw some new developments that more directly facilitated the design of behaviourally-complete objects. One was the Java programming language, which has become very popular. Java makes object-oriented programming considerably easier to implement, because of its support for memory management and garbage collection. But the reason for Java's popularity probably has more to do with its portability across multiple platforms, its security features and its Internet-readiness than its object-oriented features. Many Java programmers actually have a very poor understanding of object-oriented techniques, and this is not helped by the fact that the Java language is often taught in the same way as procedural languages. One Java textbook [Dietel1999], frequently used in college courses, does not introduce the concept of classes until page 326! The BlueJ project (see panel) is a worthy attempt to redress this situation.
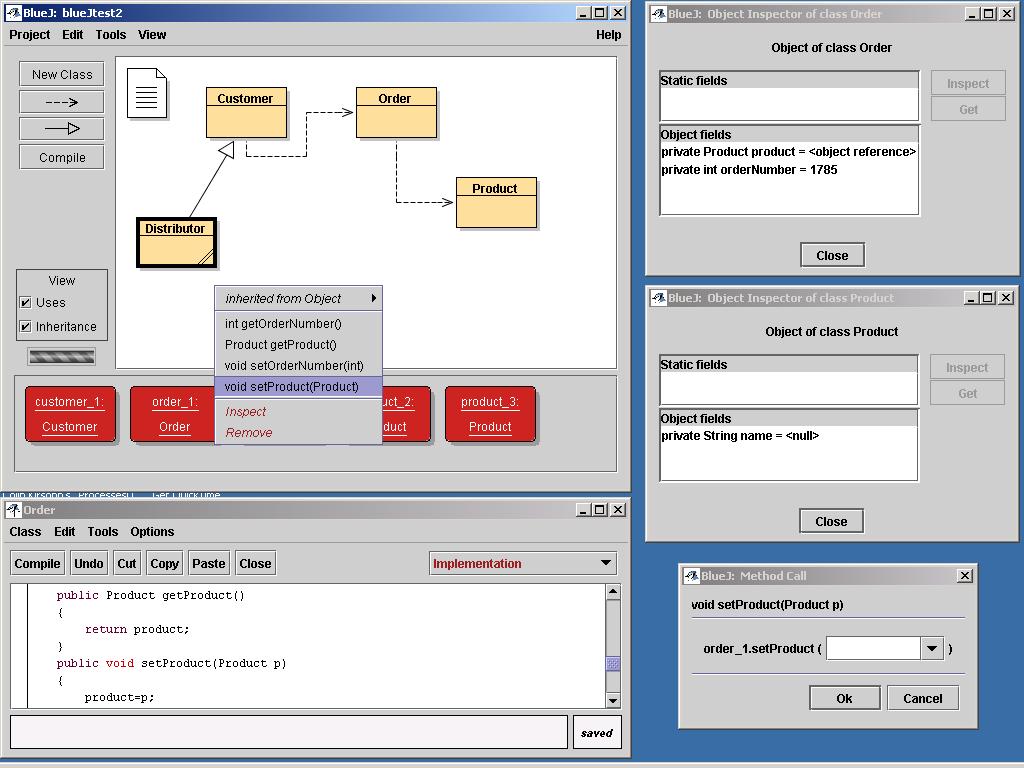
BlueJ is an open-source teaching tool for Java that is specifically designed to help people learn Java as a true object-oriented programming language. Many Java textbooks and development tools tend unconsciously to reinforce the traditional procedural language paradigm. In BlueJ the user can directly inspect individual object instances as well as the classes. The tool also eliminates the need for the programmer to write a main method - a feature of Java that can encourage procedural thinking. BlueJ is an excellent environment in which to learn Java, and one that is conceptually compatible with Naked Objects thinking. |
The state of the art
Where does this leave us, in the early years of the twenty-first century? The technical obstacles to designing and implementing object-oriented business systems have been eliminated, and object-oriented terminology has penetrated most systems development organisations to some extent. Yet core business systems design continues to separate procedure and data. They may be labelled 'procedure objects' and 'data objects' but the separation is nonetheless real. And that separation is contrary to the most important principle of object-orientation: behavioural completeness.
Some people see the idea of behaviourally-complete objects as impossibly idealistic, simply not realizable in any practical systems design. Some argue that the separation of process and data at some level is necessary and desirable for business systems: with object-oriented techniques, that separation merely occurs at a higher level of abstraction than with classical systems design. Others regard the continued separation of procedure and data as unimportant: provided that an organization is getting some benefit from the application of object-oriented principles, they say, it matters not how, or how deeply, they apply them. This point of view is an example of the relativist argument that there is no such thing as 'good' OO design, any more than 'good' English, or 'good' music - it is what works for you that counts.
Actually, there is a growing consensus about what constitutes good OO design and implementation, reflected in a range of widely-credited books on OO design patterns, heuristics and techniques. See, for example, Gamma et al[Gamma1995], Fowler[Fowler2000], Meyer [Meyer1998], Hunt and Thomas[Hunt2000], and Riel[Riel1996]. Although the phrase 'behavioural completeness' is not common, many of the heuristics point to this idea. Riel, for example, identifies these heuristics:
- 'Keep related data and behaviour in one place.'
- 'Distribute system intelligence horizontally as uniformly as possible, that is, the top-level classes in a design should share the work uniformly.'
- 'Do not create god classes/objects in your system. Be very suspicious of a class whose name contains Driver, Manager, System or Subsystem.'
Attempts to prove formally that one set of design heuristics is better than another are seldom effective, in any domain. And for business systems design there is hardly ever an opportunity to develop the same system in two different ways and compare them. Some limited experiments have produced results that support behavioural completeness. For example, one of the few documented examples of the same system being designed using the two distinct approaches [Sharble1993] when subsequently analysed using accepted metrics such as message traffic [Wirfs-Brock1994] indicated that the approach where the core business entities were more behaviourally-complete had less coupling between the objects and should therefore be easier to extend or modify. Another study compared two designs, one of which clearly featured 'god classes' [Deligiannis2002] and measured the effort required (by programmers unfamiliar with either design) to introduce the same modification: again, the more behaviourally-complete style of design won.
We would not claim that such limited experiments form a conclusive proof. In any event our aim here is not to prove the advantages of behavioural completeness to those who are sceptical. Rather, we want to help the much larger community of developers who identify strongly with the goal of designing systems from behaviourally-complete objects - indeed that was what attracted them to object-orientation in the first place - but who tell us that it never quite seems to work out that way. They tell us that business system designs seem to degenerate into procedure and data with almost the same inevitability that milk decays into curds and whey, or salad dressing into oil and vinegar, and they can't explain why that should be.
Copyright (c) 2002 nakedobjects.org You may print this document for your own personal use, or you may copy it in electronic form for access within your organisation, provided this notice is preserved.