Naked Objects
By Richard Pawson and Robert Matthews
The anatomy of a naked object
Fields
When the framework's viewing mechanism portrays a business object
in one of its opened views (most commonly the 'form' view), it looks to
see if the object has any publicly available accessor methods that
return an object of the org.nakedobjects.object.Naked
type, and if so displays that object in a field. These accessor
methods have many uses: they are used by the persistence mechanism,
and may be called by other objects. But it is often convenient to think
of them, in the first instance, as rendering an internal attribute
visible to the user.
Fields can be divided into three categories: values, associations, and multiple associations. These can all be seen in the screenshot below, where the values appear as characters on a line and are editable, and the associations show up as icons. For a multiple association, the field can show more than one icon.
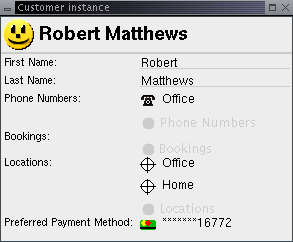
The label, or field name, is generated from the name of the accessor method (it is the method name without its 'get' prefix, and with spaces added where a capital letter is found). An accessor method often shares the same name as the variable it accesses, but not always. Remember that it is the method name and not the variable name that is used by the framework to label the field displayed to the user.
Values
Simple unshared data values are restricted to classes of the type
org.nakedobjects.object.NakedValue. The framework
provides TextString, Date,
Time, WholeNumber (in the
org.nakedobjects.object.value package) and several others. Use these classes to model all
values that might need to be accessed outside the business object -
for example to be displayed to the user or made persistent in a
database. Programmers may define new NakedValue types,
for example to handle scientific units of measurement. You may use
other Java classes and primitives such as
java.lang.String or int inside a method for
strictly local purposes, but you cannot display them directly via the
viewing mechanism.
Each value object must be declared and initialized, and must be made available through an accessor method:
public class Customer extends AbstractNakedObject {
private final TextString lastName;
private final TextString firstName;
public Customer() {
firstName = new TextString();
lastName = new TextString();
}
public TextString getLastName() {
return lastName;
}
public TextString getFirstName() {
return firstName;
}
}
The lastName and
firstName variables are both
TextString objects and are used to store simple
textual information. All value objects are mutable and should be
declared as private and final so that a specific value object referenced
by a field is never replaced. The value that it contains (e.g. the
last name) may change, but only by getting hold of the
value object and invoking one of the change methods that it provides.
This convention helps to ensure that value objects are not
inadvertently shared between business objects by attempting to copy a
value from one field to another.
Since they are marked as final, these variables must be initialized before the containing object can be used. This must be done either after the declaration or, as we have shown, in a suitable constructor. All value object classes have a zero parameter constructor, so they can be instantiated without you having to provide an initial value.
As all fields containing a value object are marked as final, only
a get... method is required. The beauty of the
value objects is that the framework takes complete care of them. If
the user wants to change a value then the framework asks the value
object to change itself. If the user interface needs to know what
possible values there are (for the
org.nakedobjects.object.value.Option value object,
say) then the framework asks that value object directly. As
programmers our job is done when we decide to use a specific type of
value object and declare it as described.
Value fields can be made read-only, so the field cannot be
edited. This is indicated to the user by the removal of the light
grey line underneath the field's text. The field can be set at any
time by a call to the setAbout method on the value
object and passing in an About object - after which it
cannot be changed. Suitable
org.nakedobjects.object.control.About objects to make
a field read-only or read-write can be
obtained from the
org.nakedobjects.object.control.FieldAbout class and
are called READ_ONLY and
READ_WRITE respectively. Commonly, value
objects are set to read-only when they are created, as shown in the
following code taken from the Booking class:
public Booking() {
reference = new TextString();
reference.setAbout(FieldAbout.READ_ONLY);
status = new TextString();
status.setAbout(FieldAbout.READ_ONLY);
}
One-to-one associations
A one-to-one association is where one business object has a field
that contains a reference to another business object. (A business
object is an object of the type
org.nakedobjects.object.NakedObject - any other type
of object is ignored by the framework). This assocation is
essentially achieved just by implementing the standard accessor
methods getVariable
and
setVariable
. The following code, taken
from the Booking class, shows a reference variable and
its two accessor methods. You will see also that both the
getDropOff and the setDropOff
methods have had specific calls added within them:
public class Booking extends AbstractNakedObject {
private Location dropOff;
public Location getDropOff() {
resolve(dropOff);
return dropOff;
}
public void setDropOff(Location newDropOff) {
dropOff = newDropOff;
objectChanged();
}
}
In the getDropOff method, we can see a
resolve call, which is a static method provided in the
superclass hierarchy. The purpose of the resolve call
is to ensure that the referenced object (in this case the
Location held in the DropOff field)
actually exists, fully formed, in memory. The fact that the
Booking object has all its data loaded does not imply
that all the other objects it references are also complete: if the
framework operated that way, loading a single object could take a long
time! Instead the framework endeavours to load objects from storage
only when they are needed.
This is best explained with an example. In the image below the left hand side (with the blue background) shows the user's view. The right hand side (grey background) is a portrayal of what is happening in working memory:
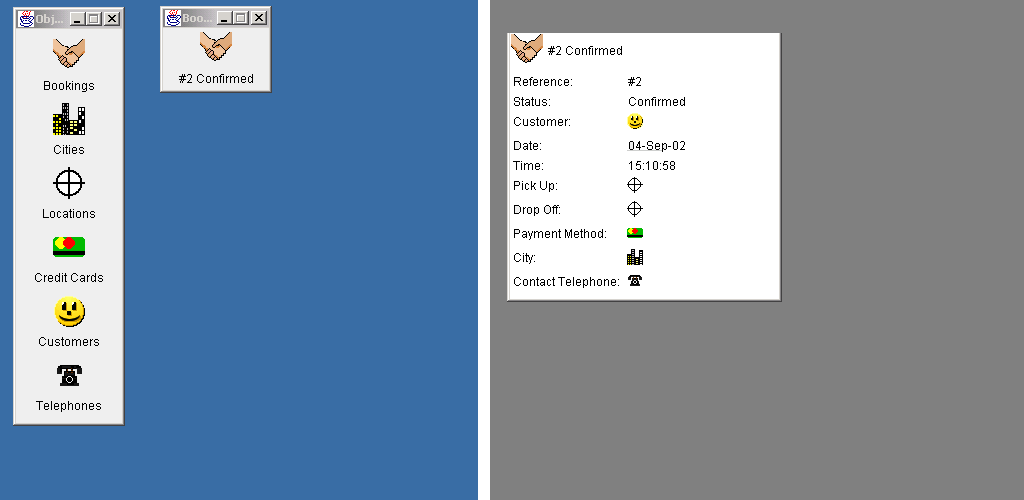
In this first screen, the user has retrieved the #2
Confirmed booking from storage and displayed it as an icon.
On the right-hand side we can see that a booking object has been
instantiated in memory, and that the value fields, which are an
integral part of the object, have been retrieved from storage. In this
case, those value fields provide sufficient information for the booking
object's title to be generated (specifically from the
Reference and Status fields).
For each of the objects associated with that booking, a new instance of
the appropriate type has been created within the association field, but
none of those objects have yet been resolved. We have portrayed this
graphically by using icons without titles.
The user now opens up the booking object to show the form view. All value fields and all associated objects are now displayed:
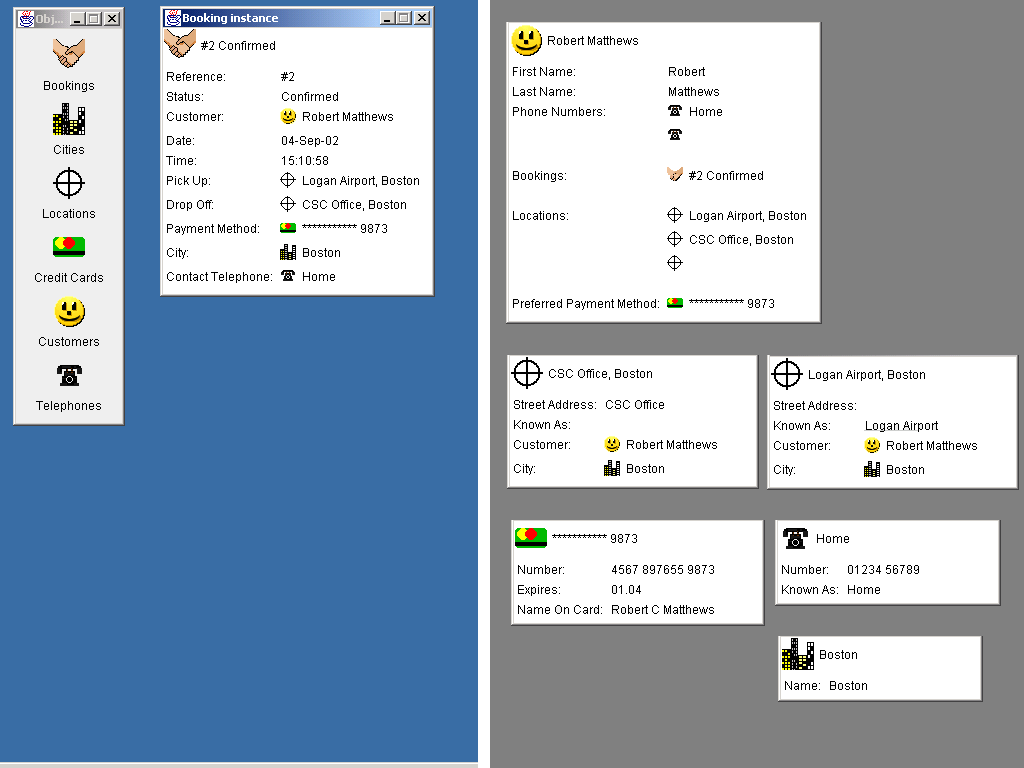
In order to display the titles of each of the associated objects (such as the customer for that booking) the framework has automatically resolved those objects. (The booking object still exists in memory, but this is not shown for reasons of space). Each of these objects has now had each of its value fields retrieved from storage, but where the objects contain references (associations) to other objects, these have been instantiated, but not themselves resolved. If the associated object has already been retrieved then that reference is used. In our example this has happened with the Home telephone, the first two locations and the credit card because they have all been used by the booking. The second telephone and the third location have not been used yet and therefore exist only as skeletal objects.
The user now opens up a form view of the customer object, in this case as a new window:
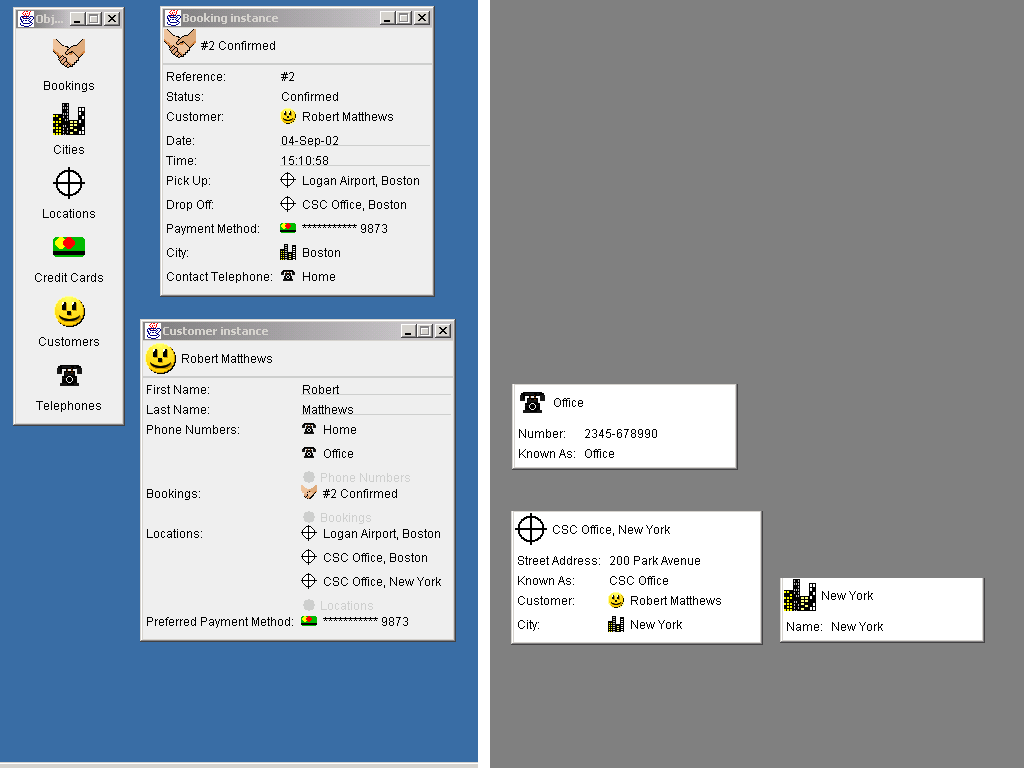
On the right hand side we can see that this object has now been resolved in memory. Most of the objects that it refers to are already available as they have been used previously, except for the Office telephone and CSC Office location which now must be read in. Note that the location object has a title that uses both the Known As value field and the City association field. The generation of the title therefore forces the automatic retrieval of the New York object.
In consequence, accessors for fields that reference other business
objects (such as the getDropOff in the last piece of code
we looked at) should start with an
explicit attempt to resolve the referenced object. The
resolve method checks the reference, and if it is
valid but has not yet been resolved, the framework issues a resolve
request to the object store. The object store responds to this by
loading the missing data into the object. Alternatively, if the
argument is null, or if the referenced object has already
been resolved, then the request is simply ignored. Hence, when this
method returns we can be assured that the referenced object has been
resolved and can be used safely. After the reference has been resolved
it is returned to the caller of the accessor method in the normal
way.
In the setDropOff method above,
after the assignment has been made, objectChanged is
called. This notifies the framework that the object has changed.
In response the framework updates the persisted version of the
object, and notifies the other viewers of this object so that their
displays can be updated. If you forget to include the
objectChanged call within a set...
method then you could find that changes to the object are not being
persisted, your display is not updating properly, and, if the object
is being shared, that other users are working with non-current
information.
It is common to control association fields so they can be made inaccessible or read-only, or so that they will only accept certain objects. When an association is marked as inaccessible the field in which it would be normally shown will not show up in the view. If the field is read-only it will not allow objects (of its type) to be dropped into it, flashing red if the user attempts to do so.
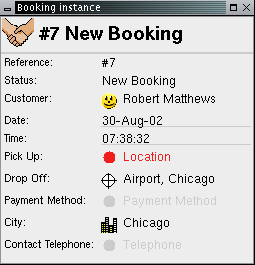
An association field is controlled through an
about... method whose name is based on the field's
name without the 'get' or 'set' prefix. This method must accept one
parameter, which must be the same type as specified in the
get... and set... methods, and
return an About object. The following example would
make the Drop Off field (as identified from the
getDropOff method) read-only:
public About aboutDropOff(Location location) {
return FieldAbout.READ_ONLY;
}
In addition to the control that is exerted over the accessor
method, the About object can supply a name that is used
to replace the field's label. This mechanism can be used to localize
the names of the fields when the system is used internationally.
One-to-many associations
A one-to-many association is where a field contains references to
a number of other business objects. This is achieved by specifying
the field as containing an
org.nakedobjects.object.collection.InternalCollection
- a specialized collection that is provided by the Naked Objects
framework. This InternalCollection is itself a type of
org.nakedobjects.object.NakedObject, and can therefore
be 'seen' by other elements of the framework such as the viewing and
persistence mechanisms. The InternalCollection
becomes a composite part of the business object and is responsible
for managing the references to the other business objects. It provides
methods to add and remove references to business objects and ensures that they all conform to a specified business type. In a future release it will
provide additional methods for sorting and other operations.
The following example, taken from the Customer
class, shows two collections being declared along with the
appropriate accessor methods. The collections are being set up to
maintain a number of Location and
Telephone objects:
public class Customer extends AbstractNakedObject {
private final InternalCollection locations;
private final InternalCollection phoneNumbers;
public Customer() {
locations = new InternalCollection(Location.class, this);
phoneNumbers = new InternalCollection(Telephone.class, this);
}
public final InternalCollection getLocations() {
return locations;
}
public final InternalCollection getPhoneNumbers() {
return phoneNumbers;
}
}
The
org.nakedobjects.object.collection.InternalCollection
variables are marked as final to ensure that they remain part of the
customer object and are never replaced. The contents of the
collections are changed by invoking methods upon the collection
object itself. A normal get... accessor is declared,
but being marked final there is no set...
method.
As the collection is a composite part of the customer object it
is created when the customer is created. The
InternalCollection's own constructor requires us to
specify the type of objects it will hold, as a
java.lang.Class object; and which object it belongs to. (Unlike
the other fields, the type cannot be specified within the variable
declaration, nor does it figure in the method signature.)
As with the value objects, the framework takes care of managing
the collections. Whenever the user adds an object to a field that
uses an InternalCollection, or a method adds an
element to the collection, the framework checks the type, adds the
object to the collection, and notifies the object store so the
persisted data can be updated. Whenever the user uses an element
from the field, or another method accesses the collection's elements,
then those elements are resolved before they are made
available.
One-to-many associations can also be made inaccessible or read-only, in the same way as one-to-one associations. Additional control over the adding and removing of specific objects from the collection will be added to the framework in the near future. When an association is marked as inaccessible the field in which it would be normally shown will not be added to the view. When marked as read-only a field will not allow objects (even of the correct type) to be dropped into it; the grey 'hole' on the screen that normally shows where an object can be dropped will not be there.
Controlling a one-to-many association field is done through an
about... method whose name is based on the field's
name without the 'get' prefix. This method must return an
About object and have no parameters. The following
example would make the Locations field (as identified
from the getLocations method) read-only:
public About aboutLocations() {
return FieldAbout.READ_ONLY;
}
Bidirectional associations
So far we have considered how one object knows about another object - a one-way association. Often this is enough, but sometimes the object that is being referenced also needs to know about the object that is referencing it. Take, for example, an ordering system. An order object will typically hold a reference to the customer who placed the order. However, it may also be useful to be able to get directly from a customer object to his current order, perhaps even to all his orders. To allow this, the customer needs to keep a reference to the order object. This can be achieved by adding a field to the customer class, containing either a single order object, or a collection of orders.
Keeping references within both objects in a relationship means that the user can find all of the related objects when given either of the objects as a starting point. That is, the association between the objects is bidirectional.
In principle this is simple to implement: you define the fields and suitable accessor methods in both objects, each holding reference to objects of the other type. However, in order to specify such a relationship the user would first have to drop one object into the appropriate field in a second object, and then drop the second object back into the corresponding field in the first object.
This would be tedious and prone to error. The obvious solution
would be to modify the set... methods so that they
call each other, thus causing both references to be
set... up in one operation. However, you then need to
ensure that you don't go into an infinite loop by calling the other
object's set method repeatedly. You would also need to write the
functionality needed to delete or clear a relationship when required.
This complex process gets even worse if one side is an
InternalCollection.
The Naked Objects framework simplifies all this through the
optional use of a pair of associateVariable
and dissociateVariable
methods to set and
reset the association respectively. If present these two methods will
be called in preference to the set method, or instead of accessing
the internal collection and adding a reference to it or removing one
from it. Both of these new methods must correspond to the
getVariable
method in name and accept one
parameter. The parameter should be of the type of business object
returned by the accessors, or if the field contains an
org.nakedobjects.object.collection.InternalCollection,
the type that the collection was initialized with.
The relationship between the Customer and the
Booking objects in the ECS application shows how this
works. The following code from the Customer class
shows the InternalCollection being declared,
initialized and made accessible. It also shows how the association
methods associateBookings and
dissociateBookings are both specified to expect a
Booking object as this is the type specified when the
internal collection was initialized.
public class Customer extends AbstractNakedObject {
private final InternalCollection bookings;
public Customer() {
bookings = new InternalCollection(Booking.class, this);
}
public final InternalCollection getBookings() {
return bookings;
}
public void associateBookings(Booking booking) {
getBookings().add(booking);
booking.setCustomer(this);
}
public void dissociateBookings(Booking booking) {
getBookings().remove(booking);
booking.setCustomer(null);
}
}
With the two association methods in place, dropping a
Booking object onto the grey hole on the
Bookings field within a Customer object
will cause the associateBookings method to be invoked
rather than getBookings.
When the associateBookings method is called it
takes on the responsibility of adding the Booking
object to the customer's collection of bookings, thereby setting up
the forward link. In addition this method asks that booking to set
its own customer field to refer to this booking, which forms the
backlink.
The dissociate method is used to reverse this by removing the
booking from the collection and setting the booking's customer field
to null, i.e. removing the forward and backlinks.
We probably also want to be able to initiate this bi-directional association from the other object - that is, when a Customer object is dropped onto the Customer field within the Booking, then the customer field is set up with that customer object, and the Booking object adds itself to the set of bookings for that customer.
The following code shows the associate and dissociate methods
that we must add to the Booking class to achieve this.
To keep them simple they are implemented so that they only call the
corresponding method in the Customer class. This avoids
duplicating the code that manages the association. As in the
Customer class, the original accessor and mutator
methods remain as they are. These are called by the association
methods, and are also used for persisting the object:
public class Booking extends AbstractNakedObject {
private Customer customer;
public void associateCustomer(Customer customer) {
customer.associateBookings(this);
}
public void dissociateCustomer(Customer customer) {
customer.dissociateBookings(this);
}
public Customer getCustomer() {
resolve(customer);
return customer;
}
public void setCustomer(Customer newCustomer) {
customer = newCustomer;
objectChanged();
}
}
Now dropping a Customer object onto the grey
hole in the Customer field within a
Booking object will cause the
associateCustomer method to be called instead of
setCustomer. This invokes the
associateBookings method (in the
Customer object) that we looked at earlier. As before
this method adds the booking object to its bookings collection,
setting up the backlink, and then calls the
setCustomer method back in the
Booking object, thereby setting up the forward link.
Bidirectional associations are coded in the same way whether they are one-to-one, one-to-many, or many-to-many. All that differs is whether we are adding or removing elements from a collection or a single object.
The prefixes 'add' and 'remove' can be used instead of the
prefixes 'associate' and 'dissociate'. Methods using these prefixes
read more easily when used with an internal collection. For example
the Customer class could equally be written as
follows:
public class Customer extends AbstractNakedObject {
private final InternalCollection bookings;
public Customer() {
bookings = new InternalCollection(Booking.class, this);
}
public void addBookings(Booking booking) {
getBookings().add(booking);
booking.setCustomer(this);
}
public void removeBookings(Booking booking) {
getBookings().remove(booking);
booking.setCustomer(null);
}
public final InternalCollection getBookings() {
return bookings;
}
}
The associate and dissociate
methods can be used for other purposes as well, such as setting two
fields at once. For example in the Booking object
when a Location is dropped onto the Pick
Up or Drop Off field, then as well as
setting the targeted field, the booking's City field
will also be set with the same City as that contained
in the Location object just dropped. This is achieved
through the following code:
public void associateDropOff(Location newDropOff) {
setDropOff(newDropOff);
setCity(newDropOff.getCity());
}
public void associatePickUp(Location newPickUp) {
setPickUp(newPickUp);
setCity(newPickUp.getCity());
}
Derived fields
If a field needs to be derived dynamically from other fields within the object then it is better to use the prefix 'derive' instead of 'get'. This will make the field read-only and non-persistent, avoiding any potential problems that could arise from the persistence mechanism attempting to store or retrieve that field from storage.
In the following example a 'due' date is calculated as being 14
days after the date held by the ordered field.
The important thing here is that a new Date object is
created from the existing one. This copy is then used to do the
calculations and it is this copy that is returned to the framework.
The principle here is that by creating a new value object you will
avoid corrupting the object's other fields.
public Date deriveDue() {
Date due = new Date(ordered);
due.add(14,0,0);
return due;
}
Ordering fields
The ordering of the fields when an object is displayed is based on
the array of accessor methods that is produced by Java's reflection
mechanism. This means the ordering depends on how the JVM you
are running collects the data about your class, and you have
no direct contol over this. You may, however, specify an order within
your class definition, which the viewing mechanism then
interprets. This is done by adding a static method called
fieldOrder that returns a
String listing the names of the fields separated by
commas. These need to be the reflected names and not the method
names. For example the string 'Pick Up' would be used to refer to
the getPickUp method. (Case is ignored.)
The following example from the Booking class
specifies an order for its fields:
public static String fieldOrder() {
return "reference, status, customer, date, time, pick up, drop off, payment method";
}
Any listed name that does not match a field is simply ignored, and fields that are not listed will be placed after all the specified fields.
Copyright (c) 2002 nakedobjects.org You may print this document for your own personal use, or you may copy it in electronic form for access within your organisation, provided this notice is preserved.